particle_gun
Aktives Mitglied
Guten Morgen Wilhelm,
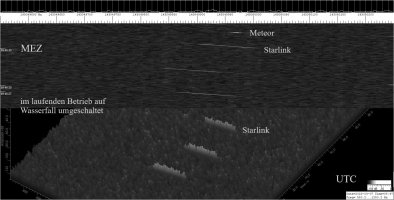
Sehr gut und vielversprechend ? Die Mask-C-RNNs sind einfach unschlagbar, ich hatte damals übrigens recht unterschiedliche Ergebnisse je nach Bildgröße bekommen und muss bei den Mikroskop Bildern Sliding Windows machen (30000x45000 Pixel). Für neue Implementierungen im Bereich Segmentierung ist das auch mein Weg, zumal die Annotationen auch Leien vornehmen können.
Nutz du immer noch PixelLib zum trainieren? Was ist dein langfristiges Ziel?
Einen schönen Sonntag
Stefanie
Sehr gut und vielversprechend ? Die Mask-C-RNNs sind einfach unschlagbar, ich hatte damals übrigens recht unterschiedliche Ergebnisse je nach Bildgröße bekommen und muss bei den Mikroskop Bildern Sliding Windows machen (30000x45000 Pixel). Für neue Implementierungen im Bereich Segmentierung ist das auch mein Weg, zumal die Annotationen auch Leien vornehmen können.
Nutz du immer noch PixelLib zum trainieren? Was ist dein langfristiges Ziel?
Einen schönen Sonntag
Stefanie